从DVC谈起
一、DVC:第一个视频压缩端到端框架
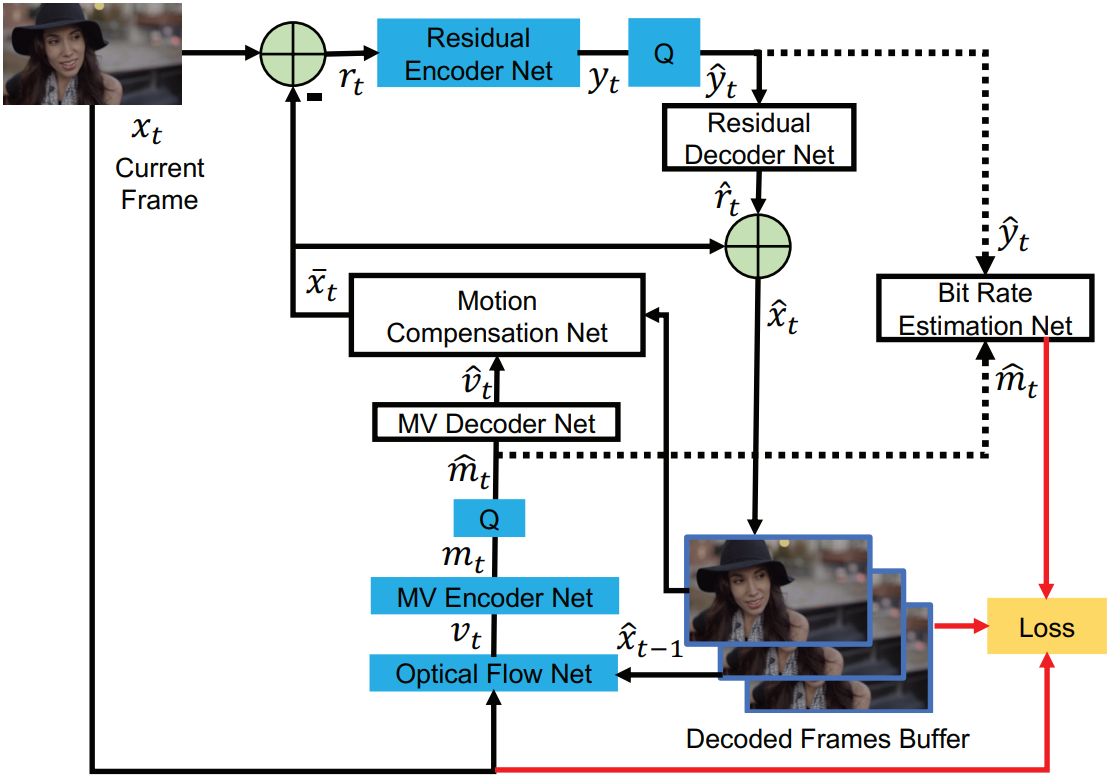
上交鲁国博士(现北理助理教授)于 CVPR2019 提出了首个端到端视频编码框架,是端到端视频编码的开山之作,整体架构与传统视频编码的架构保持一致,但整个编码器使用神经网络实现了端到端的视频编码。
DVC框架整体可以分为四个重要的子网络:
-
光流估计
-
MV编解码
-
运动补偿
-
残差编解码
-
码率估计
回顾传统编码框架,大体上可以分为六个步骤,即:运动估计、运动补偿、变换量化、反变换、熵编码、帧重建。DVC 严格按照传统框架进行设计,如图所示,其中蓝框所示模块为编码端独有,白框所示模块组成解码器,整个网络采取端到端的训练方式,整体Loss同样模仿传统率失真函数,由原始帧、重建帧和码率估计值计算得到,即:
(传统编码率失真函数为:,这里拉格朗日乘子 并未和传统编码器保持一致)
DVC 设计要点
- 原始帧和重建帧(前一帧)输入光流估计网络 Spatial Pyramid Network (SPyNet) 获得像素级运动矢量
- 运动矢量使用 Balle 所提出的经典端到端图像压缩框架进行编解码
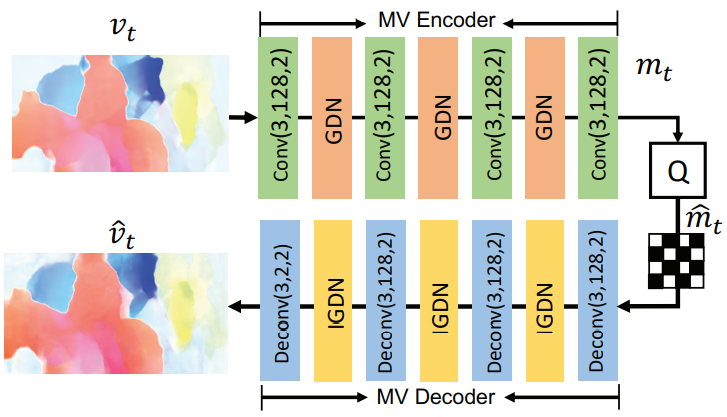
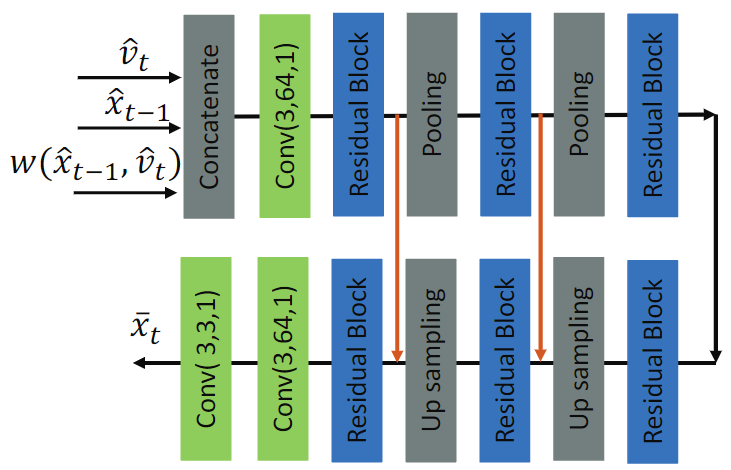
- 运动补偿网络使用卷积神经网络实现,具体如下:
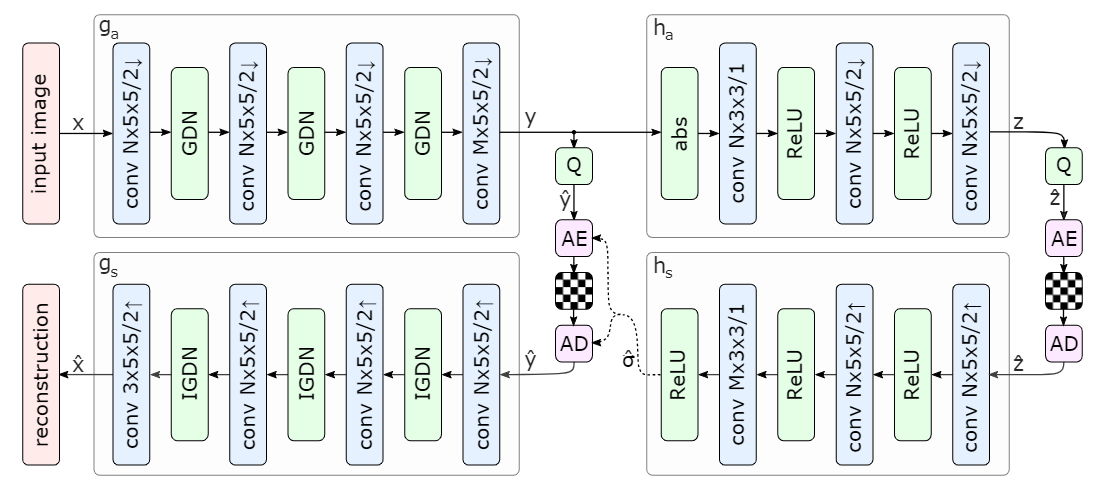
- 残差编解码网络和码率估计借鉴 Balle 端到端图像压缩改进模型:
由于该端到端框架并不是基于块的编码,且运动补偿网络将解码前一帧、运动补偿帧和运动矢量concatenate后获得补偿后帧,该过程实现了类似传统框架中的环路滤波的效果。
注意,由于量化过程不可导,这里在训练过程中增加了均匀噪声,和 Balle 的做法一致。
DVC作为端到端视频编码的开山之作,主体网络结构借鉴于 Balle 的端到端图像压缩框架,从性能上看,在低码率情况下能和 libx265 veryfast 预设下效率相当,优于 libx264,该性能表现还是比较不错的。但该架构也存在不足之处,比如文中也提到过,网络仅将前一帧作为参考帧,所以压缩性能比不过使用了多参考帧的传统框架也是理所当然的;此外,模型似乎局限于较低码率场景下。考虑后续的改进,一方面可以增加多参考帧,另一方面可以改进失真度量方式,以更符合人眼主观感知特性。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!